Volumetric performance capture from minimal camera viewpoints
Andrew Gilbert1, Marco Volino2, John Collomosse 2,3 and Adrian Hilton 2 1Department of Music & Media University of Surrey, United Kingdom 2Centre for Vision, Speech & Signal Processing University of Surrey, United Kingdom 3Creative Intelligence Lab, Adobe Research appeared atEuropean Conference on Computer Vision (ECCV'18)
Abstract
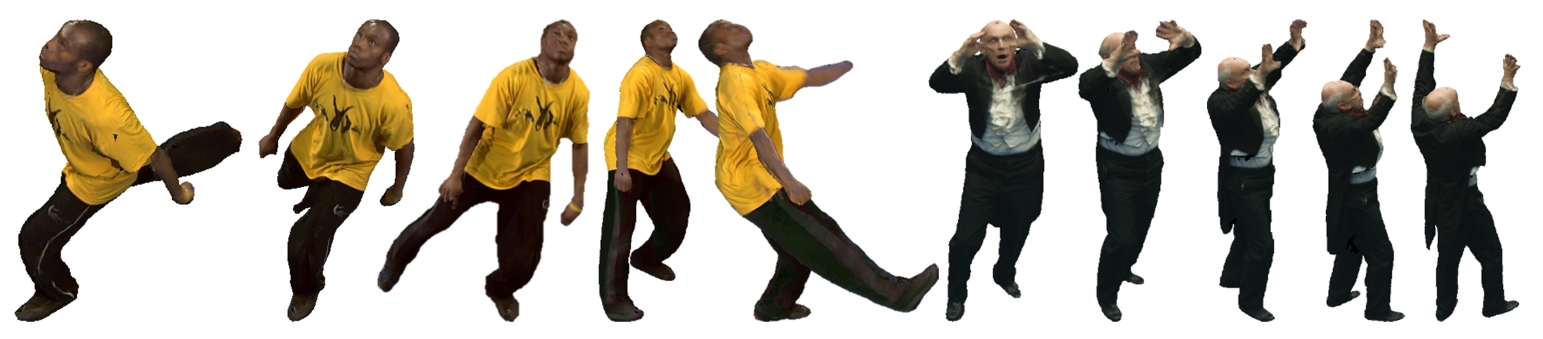
We present a convolutional autoencoder that enables high fidelity volumetric reconstructions of human performance to be captured from multi-view video comprising only a small set of camera views. Our method yields similar end-to-end reconstruction error to that of a probabilistic visual hull computed using significantly more (double or more) viewpoints. We use a deep prior implicitly learned by the autoencoder trained over a dataset of view-ablated multi-view video footage of a wide range of subjects and actions. This opens up the possibility of high-end volumetric performance capture in on-set and prosumer scenarios where time or cost prohibit a high witness camera count.
Paper

Volumetric performance capture from minimal camera viewpoints
Andrew Gilbert,
Marco Volino ,
John Collomosse and
Adrian Hilton
ECCV 2018
![]()
![]()
Citation
@inproceedings{gilbert:eccv:2018,
AUTHOR = "Gilbert, Andrew and Volino, Marco and Collomosse, John and Hilton, Adrian ",
TITLE = "Volumetric performance capture from minimal camera viewpoints",
BOOKTITLE = " European Conference on Computer Vision (ECCV'18)",
YEAR = "2018",
}